
SKYSPIN
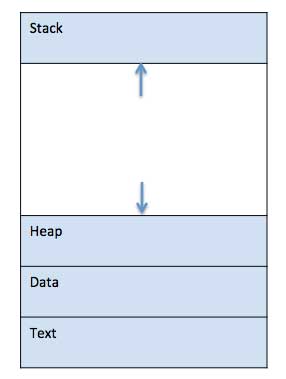
When a program is loaded into the memory and it becomes a process, it can be divided into four sections ─ stack, heap, text and data. The following image shows a simplified layout of a process inside main memory −

A part of a computer program that performs a well-defined task is known as an algorithm. A collection of computer programs, libraries and related data are referred to as a software.
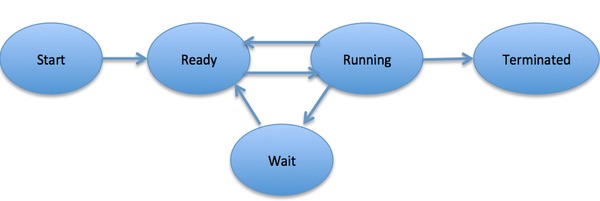
In general, a process can have one of the following five states at a time.



The architecture of a PCB is completely dependent on Operating System and may contain different information in different operating systems. Here is a simplified diagram of a PCB −
 The PCB is maintained for a process throughout its lifetime, and is deleted once the process terminates.
The PCB is maintained for a process throughout its lifetime, and is deleted once the process terminates.
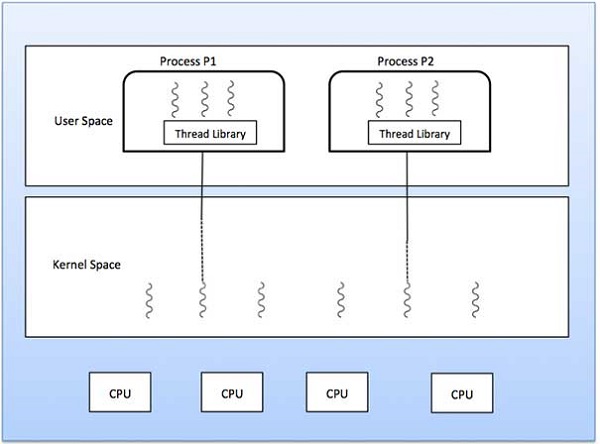
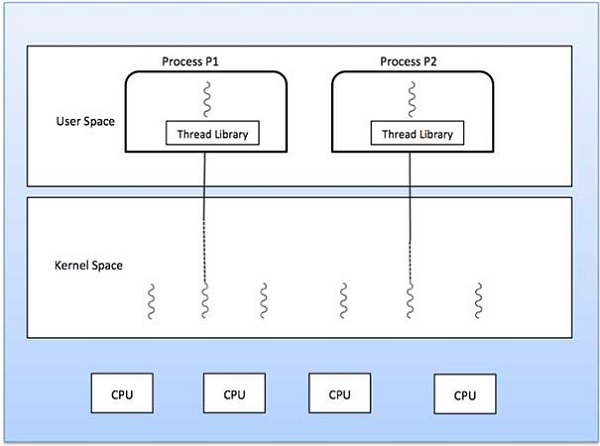
Process scheduling is an essential part of a Multiprogramming operating systems. Such operating systems allow more than one process to be loaded into the executable memory at a time and the loaded process shares the CPU using time multiplexing.
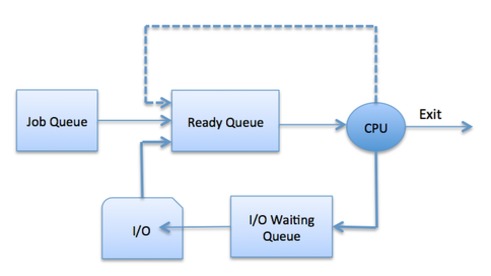
The Operating System maintains the following important process scheduling queues −
 The OS can use different policies to manage each queue (FIFO, Round
Robin, Priority, etc.). The OS scheduler determines how to move
processes between the ready and run queues which can only have one entry
per processor core on the system; in the above diagram, it has been
merged with the CPU.
The OS can use different policies to manage each queue (FIFO, Round
Robin, Priority, etc.). The OS scheduler determines how to move
processes between the ready and run queues which can only have one entry
per processor core on the system; in the above diagram, it has been
merged with the CPU.
UNIT-2(PROCESS MANAGEMENT)
Process
A process is basically a program in execution. The execution of a process must progress in a sequential fashion.A process is defined as an entity which represents the basic unit of work to be implemented in the system.To put it in simple terms, we write our computer programs in a text file and when we execute this program, it becomes a process which performs all the tasks mentioned in the program.
When a program is loaded into the memory and it becomes a process, it can be divided into four sections ─ stack, heap, text and data. The following image shows a simplified layout of a process inside main memory −
Program
A program is a piece of code which may be a single line or millions of lines. A computer program is usually written by a computer programmer in a programming language. For example, here is a simple program written in C programming language −#include <stdio.h> int main() { printf("Hello, World! \n"); return 0; }A computer program is a collection of instructions that performs a specific task when executed by a computer. When we compare a program with a process, we can conclude that a process is a dynamic instance of a computer program.
A part of a computer program that performs a well-defined task is known as an algorithm. A collection of computer programs, libraries and related data are referred to as a software.
Process Life Cycle
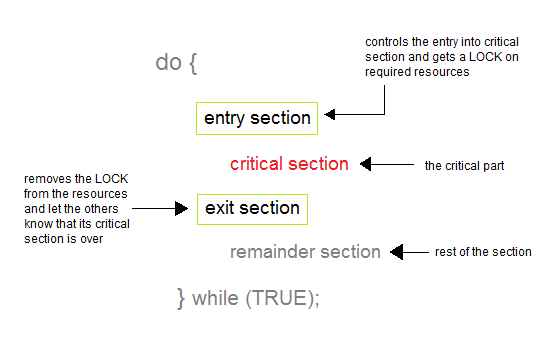
When a process executes, it passes through different states. These stages may differ in different operating systems, and the names of these states are also not standardized.In general, a process can have one of the following five states at a time.
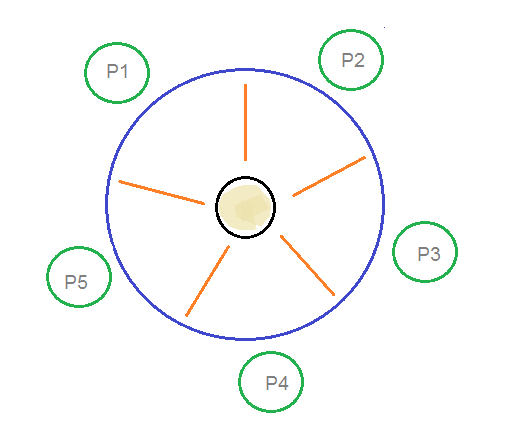
Process Control Block (PCB)
A Process Control Block is a data structure maintained by the Operating System for every process. The PCB is identified by an integer process ID (PID). A PCB keeps all the information needed to keep track of a process as listed below in the table −The architecture of a PCB is completely dependent on Operating System and may contain different information in different operating systems. Here is a simplified diagram of a PCB −
The PCB is maintained for a process throughout its lifetime, and is deleted once the process terminates.Operating System - Process Scheduling
Definition
The process scheduling is the activity of the process manager that handles the removal of the running process from the CPU and the selection of another process on the basis of a particular strategy.Process scheduling is an essential part of a Multiprogramming operating systems. Such operating systems allow more than one process to be loaded into the executable memory at a time and the loaded process shares the CPU using time multiplexing.
Process Scheduling Queues
The OS maintains all PCBs in Process Scheduling Queues. The OS maintains a separate queue for each of the process states and PCBs of all processes in the same execution state are placed in the same queue. When the state of a process is changed, its PCB is unlinked from its current queue and moved to its new state queue.The Operating System maintains the following important process scheduling queues −
- Job queue − This queue keeps all the processes in the system.
- Ready queue − This queue keeps a set of all processes residing in main memory, ready and waiting to execute. A new process is always put in this queue.
- Device queues − The processes which are blocked due to unavailability of an I/O device constitute this queue.
The OS can use different policies to manage each queue (FIFO, Round
Robin, Priority, etc.). The OS scheduler determines how to move
processes between the ready and run queues which can only have one entry
per processor core on the system; in the above diagram, it has been
merged with the CPU.Two-State Process Model
Two-state process model refers to running and non-running states which are described below − |
|||
SchedulersSchedulers are special system software which handle process scheduling in various ways. Their main task is to select the jobs to be submitted into the system and to decide which process to run. Schedulers are of three types −
Long Term SchedulerIt is also called a job scheduler. A long-term scheduler determines which programs are admitted to the system for processing. It selects processes from the queue and loads them into memory for execution. Process loads into the memory for CPU scheduling.The primary objective of the job scheduler is to provide a balanced mix of jobs, such as I/O bound and processor bound. It also controls the degree of multiprogramming. If the degree of multiprogramming is stable, then the average rate of process creation must be equal to the average departure rate of processes leaving the system. On some systems, the long-term scheduler may not be available or minimal. Time-sharing operating systems have no long term scheduler. When a process changes the state from new to ready, then there is use of long-term scheduler. Short Term SchedulerIt is also called as CPU scheduler. Its main objective is to increase system performance in accordance with the chosen set of criteria. It is the change of ready state to running state of the process. CPU scheduler selects a process among the processes that are ready to execute and allocates CPU to one of them.Short-term schedulers, also known as dispatchers, make the decision of which process to execute next. Short-term schedulers are faster than long-term schedulers. Medium Term SchedulerMedium-term scheduling is a part of swapping. It removes the processes from the memory. It reduces the degree of multiprogramming. The medium-term scheduler is in-charge of handling the swapped out-processes.A running process may become suspended if it makes an I/O request. A suspended processes cannot make any progress towards completion. In this condition, to remove the process from memory and make space for other processes, the suspended process is moved to the secondary storage. This process is called swapping, and the process is said to be swapped out or rolled out. Swapping may be necessary to improve the process mix. Comparison among Scheduler |
|||
 |
|||
Context SwitchA context switch is the mechanism to store and restore the state or context of a CPU in Process Control block so that a process execution can be resumed from the same point at a later time. Using this technique, a context switcher enables multiple processes to share a single CPU. Context switching is an essential part of a multitasking operating system features.When the scheduler switches the CPU from executing one process to execute another, the state from the current running process is stored into the process control block. After this, the state for the process to run next is loaded from its own PCB and used to set the PC, registers, etc. At that point, the second process can start executing. 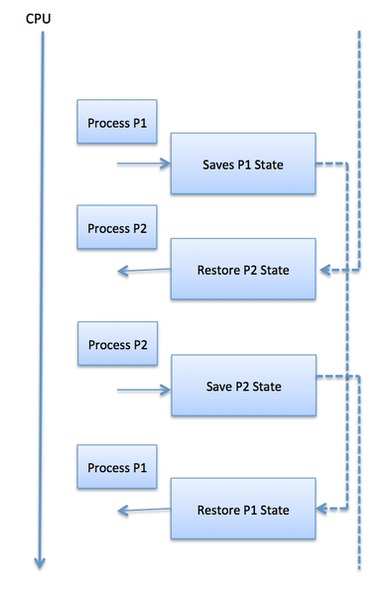 Context switches are computationally intensive since register and
memory state must be saved and restored. To avoid the amount of context
switching time, some hardware systems employ two or more sets of
processor registers. When the process is switched, the following
information is stored for later use.
Context switches are computationally intensive since register and
memory state must be saved and restored. To avoid the amount of context
switching time, some hardware systems employ two or more sets of
processor registers. When the process is switched, the following
information is stored for later use.
|
|||

Waiting time of each process is as follows − |
|||
 |
|||
Average Wait Time: (0 + 4 + 12 + 5)/4 = 21 / 4 = 5.25Priority Based Scheduling
 |
|||

Waiting time of each process is as follows −  Average Wait Time: (0 + 10 + 12 + 2)/4 = 24 / 4 = 6 Shortest Remaining Time
Round Robin Scheduling
 Average Wait Time: (9+2+12+11) / 4 = 8.5 Multiple-Level Queues SchedulingMultiple-level queues are not an independent scheduling algorithm. They make use of other existing algorithms to group and schedule jobs with common characteristics.
What is Thread?A thread is a flow of execution through the process code, with its own program counter that keeps track of which instruction to execute next, system registers which hold its current working variables, and a stack which contains the execution history.A thread shares with its peer threads few information like code segment, data segment and open files. When one thread alters a code segment memory item, all other threads see that. A thread is also called a lightweight process. Threads provide a way to improve application performance through parallelism. Threads represent a software approach to improving performance of operating system by reducing the overhead thread is equivalent to a classical process. Each thread belongs to exactly one process and no thread can exist outside a process. Each thread represents a separate flow of control. Threads have been successfully used in implementing network servers and web server. They also provide a suitable foundation for parallel execution of applications on shared memory multiprocessors. The following figure shows the working of a single-threaded and a multithreaded process. 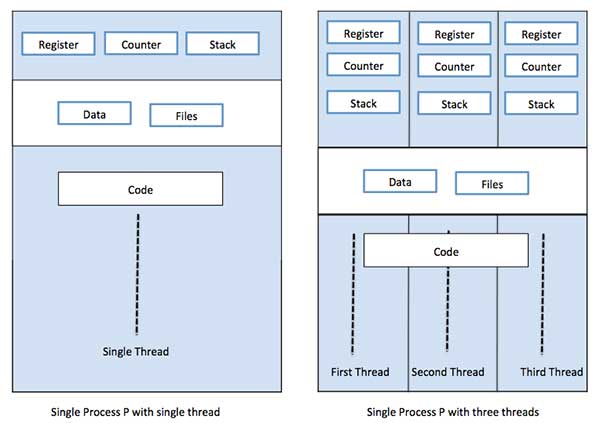
Difference between Process and Thread |
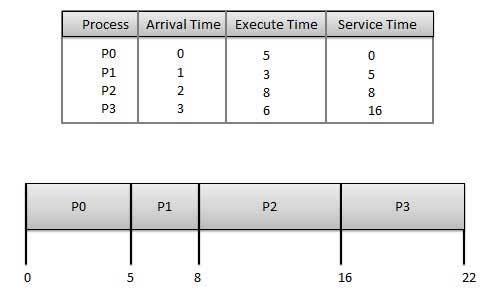 Wait time of each process is as follows −
Wait time of each process is as follows −


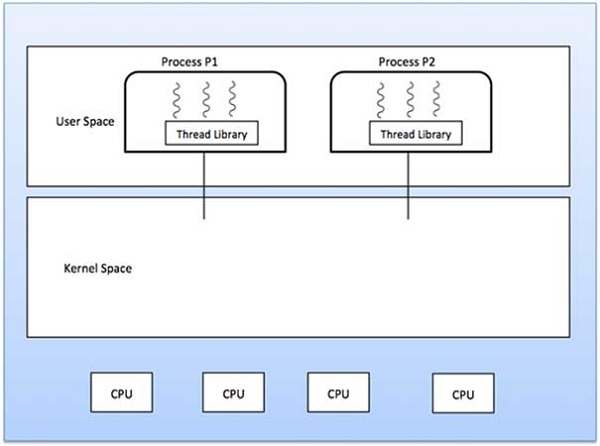
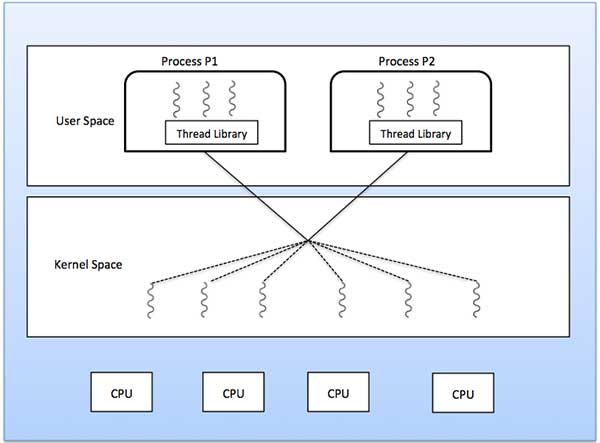
.PNG)





0 Comments