
SKYSPIN
RDBMS is used to manage Relational database. Relational database is a collection of organized set of tables related to each other, and from which data can be accessed easily. Relational Database is the most commonly used database these days.

Following is an example of single record or tuple.

Hence, the attribute Name will hold the name of employee for every tuple. If we save employee's address there, it will be violation of the Relational database model.

The three main Integrity Constraints are:
The Key attribute should never be NULL or same for two different row of data.
For example, in the Employee table we can use the attribute
Like we explained above, we cannot store Address of employee in the column for Name.
Similarly, a mobile number cannot exceed 10 digits.
If a table reference to some data from another table, then that table and that data should be present for referential integrity constraint to hold true.
On the other hand relational calculus is a non-procedural query language, which means it tells what data to be retrieved but doesn’t tell how to retrieve it. We will discuss relational calculus in a separate tutorial.
1. Basic Operations
2. Derived Operations
2. Project (∏)
3. Union (∪)
4. Set Difference (-)
5. Cartesian product (X)
6. Rename (ρ)
2. Left, Right, Full outer join (⟕, ⟖, ⟗)
3. Intersection (∩)
4. Division (÷)
Lets discuss these operations one by one with the help of examples.
If you understand little bit of SQL then you can think of it as a where clause in SQL, which is used for the same purpose.
Project operator in relational algebra is similar to the Select statement in SQL.
Syntax of Project Operator (∏)
 Query:
Query:
 Output:
Output:
Union operator is denoted by ∪ symbol and it is used to select all the rows (tuples) from two tables (relations).
Lets discuss union operator a bit more. Lets say we have two relations R1 and R2 both have same columns and we want to select all the tuples(rows) from these relations then we can apply the union operator on these relations.
Note: The rows (tuples) that are present in both the tables will only appear once in the union set. In short you can say that there are no duplicates present after the union operation.
Syntax of Union Operator (∪)
Table 1: COURSE
 Table 2: STUDENT
Table 2: STUDENT
 Query:
Query:

Output:

Note: As you can see there are no duplicate names present in the output even though we had few common names in both the tables, also in the COURSE table we had the duplicate name itself.
Lets say we have two relations R1 and R2 both have same columns and we want to select all those tuples(rows) that are present in both the relations, then in that case we can apply intersection operation on these two relations R1 ∩ R2.
Note: Only those rows that are present in both the tables will appear in the result set.
 Syntax of Intersection Operator (∩)
Syntax of Intersection Operator (∩)
Table 1: COURSE
Table 2: STUDENT
Query:
 Output:
Output:

Syntax of Set Difference (-)

Query:
Lets write a query to select those student names that are present in STUDENT table but not present in COURSE table.
 Output:
Output:

Syntax of Cartesian product (X)

 Table 2: S
Table 2: S
 Query:
Query:
Lets find the cartesian product of table R and S.
 Output:
Output:

Note: The number of rows in the output will always be the cross product of number of rows in each table. In our example table 1 has 3 rows and table 2 has 3 rows so the output has 3×3 = 9 rows.
Rename (ρ) Syntax:
ρ(new_relation_name, old_relation_name)
Table: CUSTOMER
 Query:
Query:

Output:

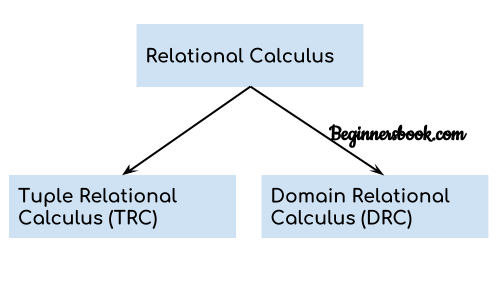
Table: Student

Lets write relational calculus queries.
Query to display the last name of those students where age is greater than 30
The result of the above query would be:
 Query to display all the details of students where Last name is ‘Singh’
Query to display all the details of students where Last name is ‘Singh’
 Output:
Output:

Again we take the same table to understand how DRC works.
Table: Student
Query to find the first name and age of students where student age is greater than 27

Note:
The symbols used for logical operators are: ∧ for AND, ∨ for OR and ┓ for NOT.
Output:
To fully understand the view of data, you must have a basic knowledge of data abstraction and instance & schema. Refer these two tutorials to learn them in detail.
We have three levels of abstraction:
At the logical level these records can be described as fields and attributes along with their data types, their relationship among each other can be logically implemented. The programmers generally work at this level because they are aware of such things about database systems.
At view level, user just interact with system with the help of GUI and enter the details at the screen, they are not aware of how the data is stored and what data is stored; such details are hidden from them.
For example: In the following diagram, we have a schema that shows the relationship between three tables: Course, Student and Section. The diagram only shows the design of the database, it doesn’t show the data present in those tables. Schema is only a structural view(design) of a database as shown in the diagram below.
The design of a database at physical level is called physical schema, how the data stored in blocks of storage is described at this level.
Design of database at logical level is called logical schema, programmers and database administrators work at this level, at this level data can be described as certain types of data records gets stored in data structures, however the internal details such as implementation of data structure is hidden at this level (available at physical level).
Design of database at view level is called view schema. This generally describes end user interaction with database systems.
To learn more about these schemas, refer 3 level data abstraction architecture.
For example, lets say we have a single table student in the database, today the table has 100 records, so today the instance of the database has 100 records. Lets say we are going to add another 100 records in this table by tomorrow so the instance of database tomorrow will have 200 records in table. In short, at a particular moment the data stored in database is called the instance, that changes over time when we add or delete data from the database.

UNIT-2 ( CHAPTER-1 THE RELATIONAL DATA MODEL AND ALGEBRA)
Basic Relational DBMS Concepts
A Relational Database management System(RDBMS) is a database management system based on the relational model introduced by E.F Codd. In relational model, data is stored in relations(tables) and is represented in form of tuples(rows).RDBMS is used to manage Relational database. Relational database is a collection of organized set of tables related to each other, and from which data can be accessed easily. Relational Database is the most commonly used database these days.
RDBMS: What is Table ?
In Relational database model, a table is a collection of data elements organised in terms of rows and columns. A table is also considered as a convenient representation of relations. But a table can have duplicate row of data while a true relation cannot have duplicate data. Table is the most simplest form of data storage. Below is an example of an Employee table.RDBMS: What is a Tuple?
A single entry in a table is called a Tuple or Record or Row. A tuple in a table represents a set of related data. For example, the above Employee table has 4 tuples/records/rows.Following is an example of single record or tuple.
RDBMS: What is an Attribute?
A table consists of several records(row), each record can be broken down into several smaller parts of data known as Attributes. The above Employee table consist of four attributes, ID, Name, Age and Salary.Attribute Domain
When an attribute is defined in a relation(table), it is defined to hold only a certain type of values, which is known as Attribute Domain.Hence, the attribute Name will hold the name of employee for every tuple. If we save employee's address there, it will be violation of the Relational database model.
What is a Relation Schema?
A relation schema describes the structure of the relation, with the name of the relation(name of table), its attributes and their names and type.What is a Relation Key?
A relation key is an attribute which can uniquely identify a particular tuple(row) in a relation(table).Relational Integrity Constraints
Every relation in a relational database model should abide by or follow a few constraints to be a valid relation, these constraints are called as Relational Integrity Constraints.The three main Integrity Constraints are:
- Key Constraints
- Domain Constraints
- Referential integrity Constraints
Key Constraints
We store data in tables, to later access it whenever required. In every table one or more than one attributes together are used to fetch data from tables. The Key Constraint specifies that there should be such an attribute(column) in a relation(table), which can be used to fetch data for any tuple(row).The Key attribute should never be NULL or same for two different row of data.
For example, in the Employee table we can use the attribute
ID to fetch data for each of the employee. No value of ID is null and it is unique for every row, hence it can be our Key attribute.Domain Constraint
Domain constraints refers to the rules defined for the values that can be stored for a certain attribute.Like we explained above, we cannot store Address of employee in the column for Name.
Similarly, a mobile number cannot exceed 10 digits.
Referential Integrity Constraint
We will study about this in detail later. For now remember this example, if I say Supriya is my girlfriend, then a girl with name Supriya should also exist for that relationship to be present.If a table reference to some data from another table, then that table and that data should be present for referential integrity constraint to hold true.
DBMS Relational Algebra
What is Relational Algebra in DBMS?
On the other hand relational calculus is a non-procedural query language, which means it tells what data to be retrieved but doesn’t tell how to retrieve it. We will discuss relational calculus in a separate tutorial.
Types of operations in relational algebra
We have divided these operations in two categories:1. Basic Operations
2. Derived Operations
Basic/Fundamental Operations:
1. Select (σ)2. Project (∏)
3. Union (∪)
4. Set Difference (-)
5. Cartesian product (X)
6. Rename (ρ)
Derived Operations:
1. Natural Join (⋈)2. Left, Right, Full outer join (⟕, ⟖, ⟗)
3. Intersection (∩)
4. Division (÷)
Lets discuss these operations one by one with the help of examples.
Select Operator (σ)
Select Operator is denoted by sigma (σ) and it is used to find the tuples (or rows) in a relation (or table) which satisfy the given condition.If you understand little bit of SQL then you can think of it as a where clause in SQL, which is used for the same purpose.
Syntax of Select Operator (σ)
 Select Operator (σ) Example
Select Operator (σ) Example
 Query:
Query: Output:
Output:
Project Operator (∏)
Project operator is denoted by ∏ symbol and it is used to select desired columns (or attributes) from a table (or relation).Project operator in relational algebra is similar to the Select statement in SQL.
Syntax of Project Operator (∏)
 Project Operator (∏) Example
Project Operator (∏) Example
In this example, we have a table CUSTOMER with three columns, we want
to fetch only two columns of the table, which we can do with the help
of Project Operator ∏.
Query: Output:
 Union Operator (∪)
Union Operator (∪)
Union operator is denoted by ∪ symbol and it is used to select all the rows (tuples) from two tables (relations).Lets discuss union operator a bit more. Lets say we have two relations R1 and R2 both have same columns and we want to select all the tuples(rows) from these relations then we can apply the union operator on these relations.
Note: The rows (tuples) that are present in both the tables will only appear once in the union set. In short you can say that there are no duplicates present after the union operation.
Syntax of Union Operator (∪)
 Union Operator (∪) Example
Union Operator (∪) Example
Table 1: COURSE Table 2: STUDENT Query: Output:
Note: As you can see there are no duplicate names present in the output even though we had few common names in both the tables, also in the COURSE table we had the duplicate name itself.
Intersection Operator (∩)
Intersection operator is denoted by ∩ symbol and it is used to select common rows (tuples) from two tables (relations).Lets say we have two relations R1 and R2 both have same columns and we want to select all those tuples(rows) that are present in both the relations, then in that case we can apply intersection operation on these two relations R1 ∩ R2.
Note: Only those rows that are present in both the tables will appear in the result set.
Intersection Operator (∩) Example
Lets take the same example that we have taken above.Table 1: COURSE
Table 2: STUDENT Query: Output: Set Difference (-)
Set Difference is denoted by – symbol. Lets say we have two relations R1 and R2 and we want to select all those tuples(rows) that are present in Relation R1 but not present in Relation R2, this can be done using Set difference R1 – R2.Syntax of Set Difference (-)
Set Difference (-) Example
Lets take the same tables COURSE and STUDENT that we have seen above.Query:
Lets write a query to select those student names that are present in STUDENT table but not present in COURSE table.
Output: Cartesian product (X)
Cartesian Product is denoted by X symbol. Lets say we have two relations R1 and R2 then the cartesian product of these two relations (R1 X R2) would combine each tuple of first relation R1 with the each tuple of second relation R2. I know it sounds confusing but once we take an example of this, you will be able to understand this.Syntax of Cartesian product (X)
Cartesian product (X) Example
Table 1: R Table 2: S Query:Lets find the cartesian product of table R and S.
Output: Note: The number of rows in the output will always be the cross product of number of rows in each table. In our example table 1 has 3 rows and table 2 has 3 rows so the output has 3×3 = 9 rows.
Rename (ρ)
Rename (ρ) operation can be used to rename a relation or an attribute of a relation.Rename (ρ) Syntax:
ρ(new_relation_name, old_relation_name)
Rename (ρ) Example
Lets say we have a table customer, we are fetching customer names and we are renaming the resulted relation to CUST_NAMES.Table: CUSTOMER
Query: Output:
DBMS Relational Calculus
What is Relational Calculus?
Relational calculus is a non-procedural query language that tells the system what data to be retrieved but doesn’t tell how to retrieve it.Types of Relational Calculus
1. Tuple Relational Calculus (TRC)
Tuple relational calculus is used for selecting those tuples that satisfy the given condition.Table: Student
Lets write relational calculus queries.
Query to display the last name of those students where age is greater than 30
{ t.Last_Name | Student(t) AND t.age > 30 }In the above query you can see two parts separated by | symbol. The second part is where we define the condition and in the first part we specify the fields which we want to display for the selected tuples.
The result of the above query would be:
Query to display all the details of students where Last name is ‘Singh’ Output: 2. Domain Relational Calculus (DRC)
In domain relational calculus the records are filtered based on the domains.Again we take the same table to understand how DRC works.
Table: Student
Query to find the first name and age of students where student age is greater than 27 Note:
The symbols used for logical operators are: ∧ for AND, ∨ for OR and ┓ for NOT.
Output:
View of Data in DBMS
Abstraction is one of the main features of database systems. Hiding irrelevant details from user and providing abstract view of data to users, helps in easy and efficient user-database interaction. In the previous tutorial, we discussed the three level of DBMS architecture, The top level of that architecture is “view level”. The view level provides the “view of data” to the users and hides the irrelevant details such as data relationship, database schema, constraints, security etc from the user.
To fully understand the view of data, you must have a basic knowledge of data abstraction and instance & schema. Refer these two tutorials to learn them in detail.
Data Abstraction in DBMS
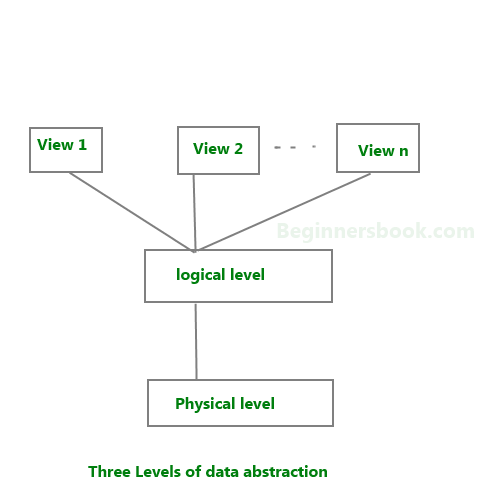
Database systems are made-up of complex data structures. To ease the user interaction with database, the developers hide internal irrelevant details from users. This process of hiding irrelevant details from user is called data abstraction.We have three levels of abstraction:
Physical level: This is the lowest level of data
abstraction. It describes how data is actually stored in database. You
can get the complex data structure details at this level.
Logical level: This is the middle level of 3-level data abstraction architecture. It describes what data is stored in database.
View level: Highest level of data abstraction. This level describes the user interaction with database system.
Example: Let’s say we are storing customer information in a customer table. At physical level
these records can be described as blocks of storage (bytes, gigabytes,
terabytes etc.) in memory. These details are often hidden from the
programmers.At the logical level these records can be described as fields and attributes along with their data types, their relationship among each other can be logically implemented. The programmers generally work at this level because they are aware of such things about database systems.
At view level, user just interact with system with the help of GUI and enter the details at the screen, they are not aware of how the data is stored and what data is stored; such details are hidden from them.
Instance and schema in DBMS
In this guide, we will learn what is an instance and schema in DBMS.DBMS Schema
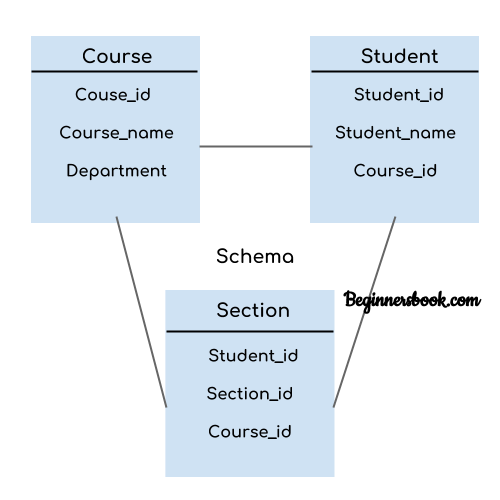
Definition of schema: Design of a database is called the schema. Schema is of three types: Physical schema, logical schema and view schema.For example: In the following diagram, we have a schema that shows the relationship between three tables: Course, Student and Section. The diagram only shows the design of the database, it doesn’t show the data present in those tables. Schema is only a structural view(design) of a database as shown in the diagram below.
The design of a database at physical level is called physical schema, how the data stored in blocks of storage is described at this level.
Design of database at logical level is called logical schema, programmers and database administrators work at this level, at this level data can be described as certain types of data records gets stored in data structures, however the internal details such as implementation of data structure is hidden at this level (available at physical level).
Design of database at view level is called view schema. This generally describes end user interaction with database systems.
To learn more about these schemas, refer 3 level data abstraction architecture.
DBMS Instance
Definition of instance: The data stored in database at a particular moment of time is called instance of database. Database schema defines the variable declarations in tables that belong to a particular database; the value of these variables at a moment of time is called the instance of that database.For example, lets say we have a single table student in the database, today the table has 100 records, so today the instance of the database has 100 records. Lets say we are going to add another 100 records in this table by tomorrow so the instance of database tomorrow will have 200 records in table. In short, at a particular moment the data stored in database is called the instance, that changes over time when we add or delete data from the database.



0 Comments